4 Enzyme-linked immunosorbest assay (ELISA)
ELISA is a standard molecular biology assay for detecting and quantifying a variety of compounds, including peptides, proteins, and antibodies in a sample. The sample could be serum, plasma, or bronchoalveolar lavage fluid (BALF).
4.1 Importance of ELISA
An antigen-specific reaction in the host results in the production of antibodies, which are proteins found in the blood. In the event of an infectious disease, it aids in the detection of antibodies in the body. ELISA is distinguishable from other antibody-assays in that it produces quantifiable findings and separates non-specific from specific interactions by serial binding to solid surfaces, which is often a polystyrene multi-well plate.
In IMPAc-TB project, it is crucial to evaluate the if the vaccine is eliciting humoral immunity and generating antibodies against vaccine antigen. ELISA will be used to determine the presence of Immunoglobulin (Ig) IgG, IgA, and IgM in the serum different time points post-vaccination.
4.1.1 Principle of ELISA
ELISA is based on the principle of antigen-antibody interaction. An antigen must be immobilized on a solid surface and then complexed with an enzyme-linked antibody in an ELISA. The conjugated enzyme’s activity is evaluated by incubating it with a substrate to yield a quantifiable result, which enables detection. There are four basic steps of ELISA:
1. Coating multiwell plate with antigen/antibody: This step depends on what we want to detect the sample. If we need to evaluate the the presence of antibody, the plate will be coated with the antigen, and vice versa. To coat the plate, a fixed concentration of antigen (protein) is added to a 96 well high-binding plate (charged plate). Plate is incubated over night with the antigen at 4 degree celsius (as proteins are temperature sensitive) so that antigens are completely bound to the well.
2. Blocking: It is possible that not each and every site of the well is coated with the targeted antigen, and there could be uncovered areas. It is important to block those empty spaces so that primary antibody (which we will add to the next step) binds to these spaces and give us false positive results. For this, microplate well surface-binding sites are blocked with an unrelated protein or other substance.Most common blocking agents are bovine serum albumin, skim milk, and casein. One of the best blocking agents is to use the serum from the organism in which your secondary (detection antibody) is raised. For example, if the secondary antibody is raised in goat, then we can use goat serum as a blocking agent.
3. Probing: Probing is the step where we add sample containing antibodies that we want to detect. This will be the primary antibody. If the antibodies against the antigen (which we have coated) are present in the sample, it will bind to the antigen with high affinity.
4. Washing: After the incubation of sample containing primary antibody, the wells are washed so that any unbound antibody is washed away. Washing solution contains phosphate buffer saline + 0.05% tween-20 (a mild detergent). 0.05% tween-20 washes away all the non-specific interactions as those are not strong, but keeps all the specific interaction as those are strong and cannot be detached with mild detergent.
5. Detection: To detect the presence of antibody-antigen complex, a secondary antibody labelled with an enzyme (usually horseradish peroxidase) is added to the wells, incubated and washed.
6. Signal Measurement: Finally to detect “if” and “how much” of the antibody is present, a chromogenic substrate (like 3,3’,5,5’-Tetramethylbenzidine) is added to the wells, which can be cleaved the the enzyme that is tagged to the secondary antibody. The color compund is formed after the addition of the substrate, which is directly proportional to the amount of antibody present in the sample. The plate is read on a plate reader, where color is converted to numbers.
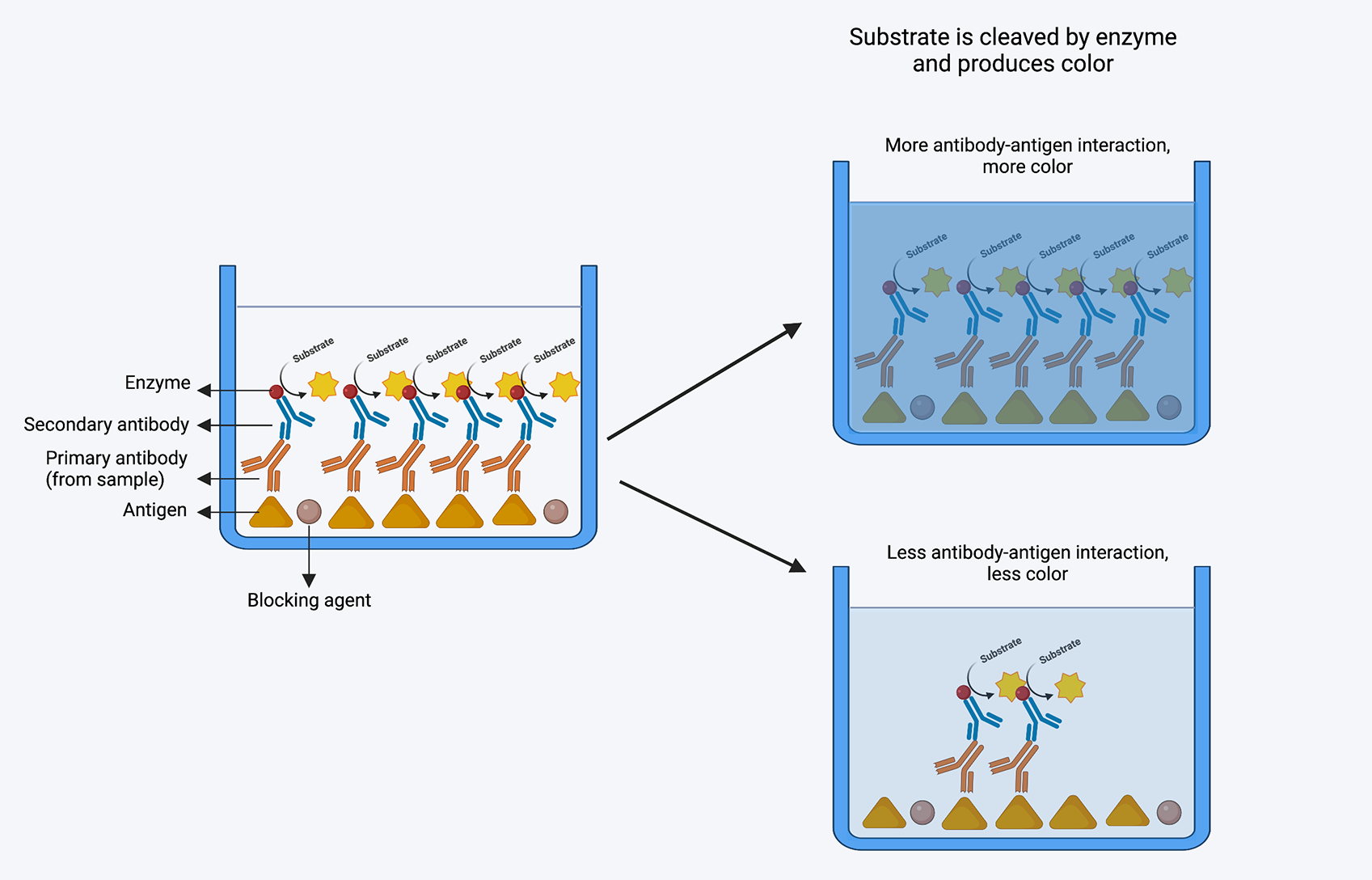
Figure 4.1: A caption
4.2 ELISA data analysis
Analysis of ELISA data is the most important part of the ELISA experiment. ELISA data can be analyzed in different ways based on how the data is acquired. There are a a few examples of the type of ELISA data :
1. With standard curve: ELISA can be used to determine the concentrations of the antigen and antibody. This type of ELISA data usually have a standard curve with different concentrations of the known analyte and the concentration in the sample is determined by extrapolating the unknown values in the curve. This type of assay is straightforward, easy to interpret and are more robust.
2. Without standard curve: Usually vaccine studies involve investigating the presence of high-affinity (and novel) antibodies against the vaccine antigens. Therefore, plotting a standard curve is not feasible as there is no previous information available for antibody concentration or type of antibody. Also, because antibody response to a vaccine will differ depending on the individual, it is not practical to generate a calibration curve from which absolute concentrations can be extrapolated. For this type of ELISA, quantification of the antibody titers is performed using serial dilutions of the test samples, and analysis can be performed using the following three methods (Hartman et al. 2018):
- Fitting sigmoid model
- Endpoint titer method 3: Absorbance summation method
Let’s have a look at these methods, how we can apply these methods in our data, and R-based packages that we can utilize to perform this analysis.
4.3 1. Curve fitting model:
The curve in ELISA data represents a plot of known concentrations versus their corresponding signal responses. The typical range of these calibration curves is one to two orders of magnitude on the response axis and two or more orders of magnitude on the concentration axis. The real curve of each assay could be easily identified if an infinite number of concentration dilutions with an infinite number of repetitions could be tested. The correct curve must be approximated from a relatively small number of noisy points, though, because there are a finite number of dilutions that may be performed. To estimate the dose-response relationship between standard dilutions, a method of interpolating between standards is required because there cannot be a standard at every concentration. This process is typically performed using a mathematical function or regression to approximate the true shape of the curve. A curve model is the name given to this approximating function, which commonly uses two or more parameters to describe a family of curves, and are then adjusted in order to find the curve from the family of curves that best fits the assay data.
Three qualities should be included in a good curve fitting model. 1. The true curve’s shape must be accurately approximated by the curve model. If the curve model does not accomplish this, there is no way to adjust for this component of the total error that results from a lack of fit. 2. In order to get concentration estimates with minimal inaccuracy, a decent curve model must be able to average away as much of the random variation as is practical. 3. A successful curve model must be capable of accurately predicting concentration values for points between the anchor points of the standard dilutions.
4.3.1 How do we perform curve fitting model
There are two major steps in performing curve fitting model for non-linear data like ELISA: 1. Finding the initial starting estimates of the parameters 2. locating the optimal solution in a region of the initial estimates
We have presented an example below where we have performed a 8-10 point serial dilution of our sample and fitted a 4 parameter curve model.
4.3.2 An example of the curve fitting model
4.3.2.1 Read in the data
This information comes from the 2018 study conducted by Hartman et al. Hartman et al. analyzed the ELISA data in their study utilizing fitted sigmoid analysis, end point titer, and absorbance summation. We utilized this information to determine whether our formulas and calculations provide the same outcomes and values as theirs.
4.3.2.2 Tidying the data
We next performed tidying the data and make it in a format so that we can plot a sigmoid curve with that.
## # A tibble: 6 × 5
## numerator denominator absorbance dilution log_dilution
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 30 4 0.0333 -3.10
## 2 1 90 3.73 0.0111 -4.10
## 3 1 270 2.34 0.00370 -5.10
## 4 1 810 1.1 0.00123 -6.10
## 5 1 2430 0.51 0.000412 -7.10
## 6 1 7290 0.22 0.000137 -8.104.3.2.3 Create function for curve fitting model
We next created the curve fitting model function by using nlsLM function from “minpack.lm” package. The purpose of nlslm is to minimize the sum square of the vector returned by the function fn, by a modification of the Levenberg-Marquardt algorithm. In the early 1960s, the Levenberg-Marquardt algorithm was developed to address nonlinear least squares problems. Through a series of well-chosen updates to model parameter values, Levenberg-Marquardt algorithm lower the sum of the squares of the errors between the model function and the data points.
## Nonlinear regression model
## model: absorbance ~ ((a - d)/(1 + (log_dilution/c)^b)) + d
## data: elisa_example_data
## a d c b
## 4.12406 0.04532 -5.31056 7.62972
## residual sum-of-squares: 0.02221
##
## Number of iterations to convergence: 9
## Achieved convergence tolerance: 1.49e-08##
## Formula: absorbance ~ ((a - d)/(1 + (log_dilution/c)^b)) + d
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## a 4.12406 0.05820 70.860 1.75e-12 ***
## d 0.04532 0.02268 1.998 0.0808 .
## c -5.31056 0.03933 -135.037 1.01e-14 ***
## b 7.62972 0.35854 21.280 2.50e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.05269 on 8 degrees of freedom
##
## Number of iterations to convergence: 9
## Achieved convergence tolerance: 1.49e-08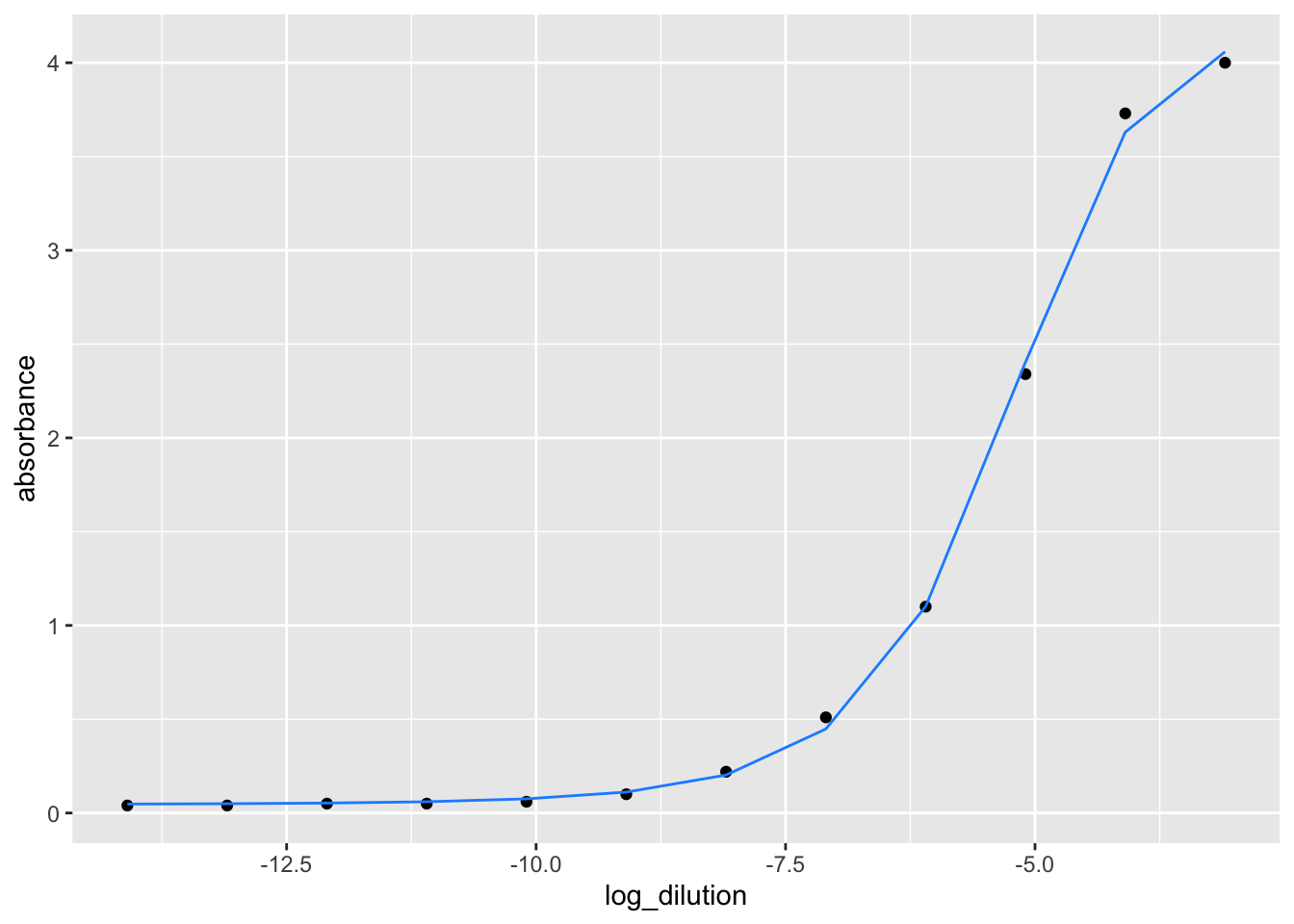
4.4 2. Endpoint titer method
The endpoint titer approach chooses an absorbance value just above the background noise (or the lower asymptotic level). The highest dilution with an absorbance greater than this predetermined value is the endpoint titer. This method is based on the assumption that a sample with a higher protein concentration will require a higher dilution factor to achieve an absorbance just above the level of background noise.
4.4.1 Create an endpoint titer function and apply it to the output of the fitted sigmoid model values.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -8.113 -8.113 -8.113 -8.113 -8.113 -8.113## [1] -8.1132854.5 Apply the fitting sigmoid model and endpoint titer function in our dataset
The presented data is from a mouse study. In this data, presence of IgG antibody has been evaluated against receptor binding domain (RBD) of SARS-CoV-2 virus in two different groups of mice. We need to elucidate which group has higher concentration of the antibodies.
4.5.0.2 Tidy the data
## # A tibble: 6 × 4
## Groups Dilution mouse_id absorbance
## <chr> <chr> <chr> <dbl>
## 1 Group 1 1/50 Mouse_1 4.1
## 2 Group 1 1/50 Mouse_2 3.9
## 3 Group 1 1/50 Mouse_3 4.3
## 4 Group 1 1/50 Mouse_4 4.2
## 5 Group 1 1/50 Mouse_5 4
## 6 Group 1 1/100 Mouse_1 3.9## Groups numerator denomenator mouse_id absorbance dilution log_dilution
## 1 Group 1 1 50 Mouse_1 4.1 0.02 -5.643856
## 2 Group 1 1 50 Mouse_2 3.9 0.02 -5.643856
## 3 Group 1 1 50 Mouse_3 4.3 0.02 -5.643856
## 4 Group 1 1 50 Mouse_4 4.2 0.02 -5.643856
## 5 Group 1 1 50 Mouse_5 4.0 0.02 -5.643856
## 6 Group 1 1 100 Mouse_1 3.9 0.01 -6.6438564.5.0.2.1 converting data into dataframe
## # A tibble: 6 × 3
## # Groups: Groups, mouse_id [6]
## Groups mouse_id data
## <chr> <chr> <list>
## 1 Group 1 Mouse_1 <tibble [10 × 5]>
## 2 Group 1 Mouse_2 <tibble [10 × 5]>
## 3 Group 1 Mouse_3 <tibble [10 × 5]>
## 4 Group 1 Mouse_4 <tibble [10 × 5]>
## 5 Group 1 Mouse_5 <tibble [10 × 5]>
## 6 Group 2 Mouse_1 <tibble [10 × 5]>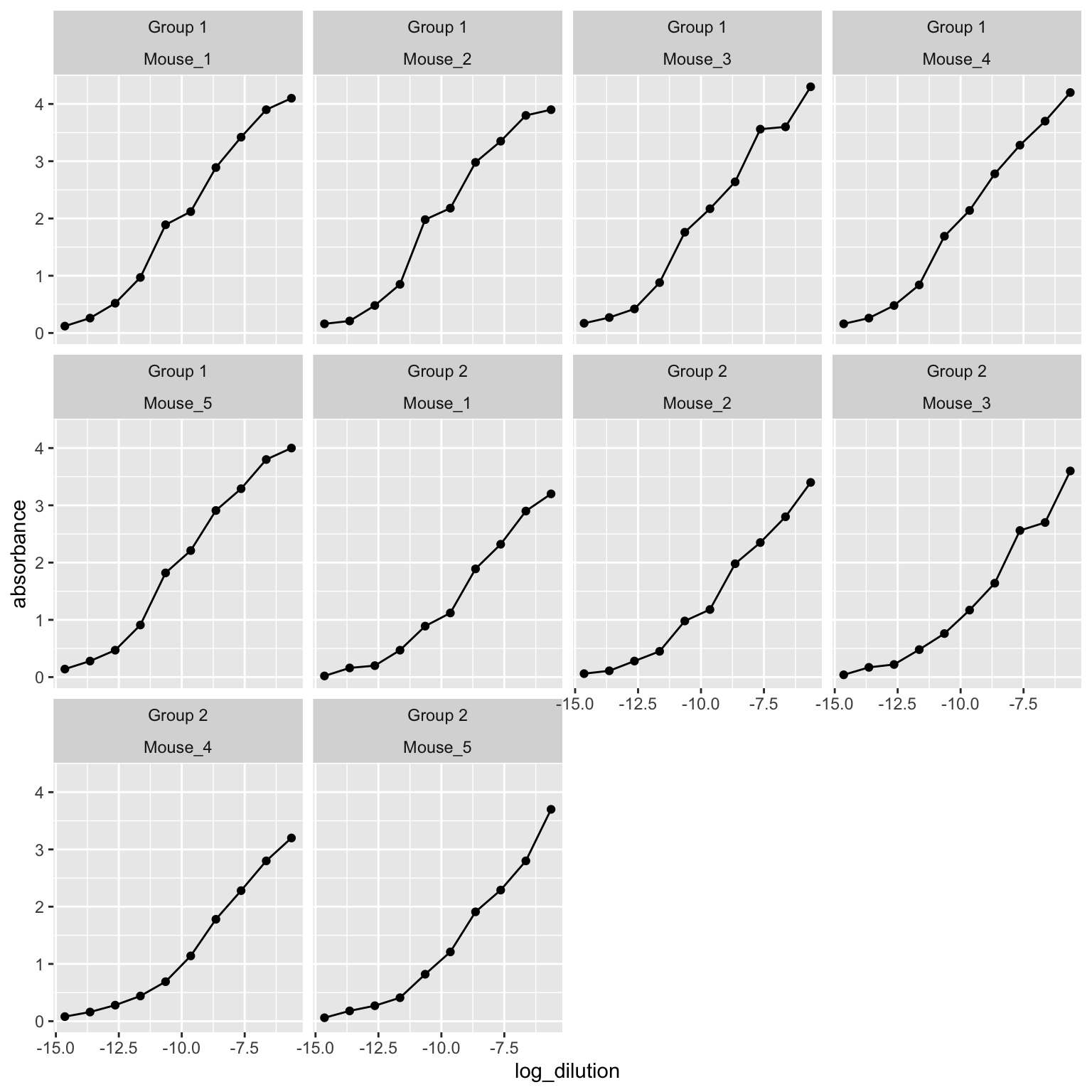
4.5.1 Creating a function for fitting model
4.5.1.1 Fitting the model into the dataset
## Nonlinear regression model
## model: absorbance ~ ((a - d)/(1 + (log_dilution/c)^b)) + d
## data: df_elisa
## a d c b
## 4.3070 -0.6009 -10.2577 5.2893
## residual sum-of-squares: 0.1199
##
## Number of iterations to convergence: 7
## Achieved convergence tolerance: 1.49e-084.5.1.2 Apply the fitted model function to the whole dataframe
## # A tibble: 6 × 4
## # Groups: Groups, mouse_id [6]
## Groups mouse_id data fitted_data
## <chr> <chr> <list> <list>
## 1 Group 1 Mouse_1 <tibble [10 × 5]> <nls>
## 2 Group 1 Mouse_2 <tibble [10 × 5]> <nls>
## 3 Group 1 Mouse_3 <tibble [10 × 5]> <nls>
## 4 Group 1 Mouse_4 <tibble [10 × 5]> <nls>
## 5 Group 1 Mouse_5 <tibble [10 × 5]> <nls>
## 6 Group 2 Mouse_1 <tibble [10 × 5]> <nls>4.5.1.3 Take out the summary of the data
## Nonlinear regression model
## model: absorbance ~ ((a - d)/(1 + (log_dilution/c)^b)) + d
## data: df_elisa
## a d c b
## 4.3070 -0.6009 -10.2577 5.2893
## residual sum-of-squares: 0.1199
##
## Number of iterations to convergence: 7
## Achieved convergence tolerance: 1.49e-084.6 Create function of Fitted model and endpoint titer, where the output of the fitted model data will be the input of the endpoint titer
4.6.0.1 Apply the fitted model fuction into the nested data and use the output of the fitted data as the input for endpoint titer value evaluation
4.6.0.1.1 Run fitted model on the data
## # A tibble: 6 × 4
## # Groups: Groups, mouse_id [6]
## Groups mouse_id data fitted_data
## <chr> <chr> <list> <list>
## 1 Group 1 Mouse_1 <tibble [10 × 5]> <nls>
## 2 Group 1 Mouse_2 <tibble [10 × 5]> <nls>
## 3 Group 1 Mouse_3 <tibble [10 × 5]> <nls>
## 4 Group 1 Mouse_4 <tibble [10 × 5]> <nls>
## 5 Group 1 Mouse_5 <tibble [10 × 5]> <nls>
## 6 Group 2 Mouse_1 <tibble [10 × 5]> <nls>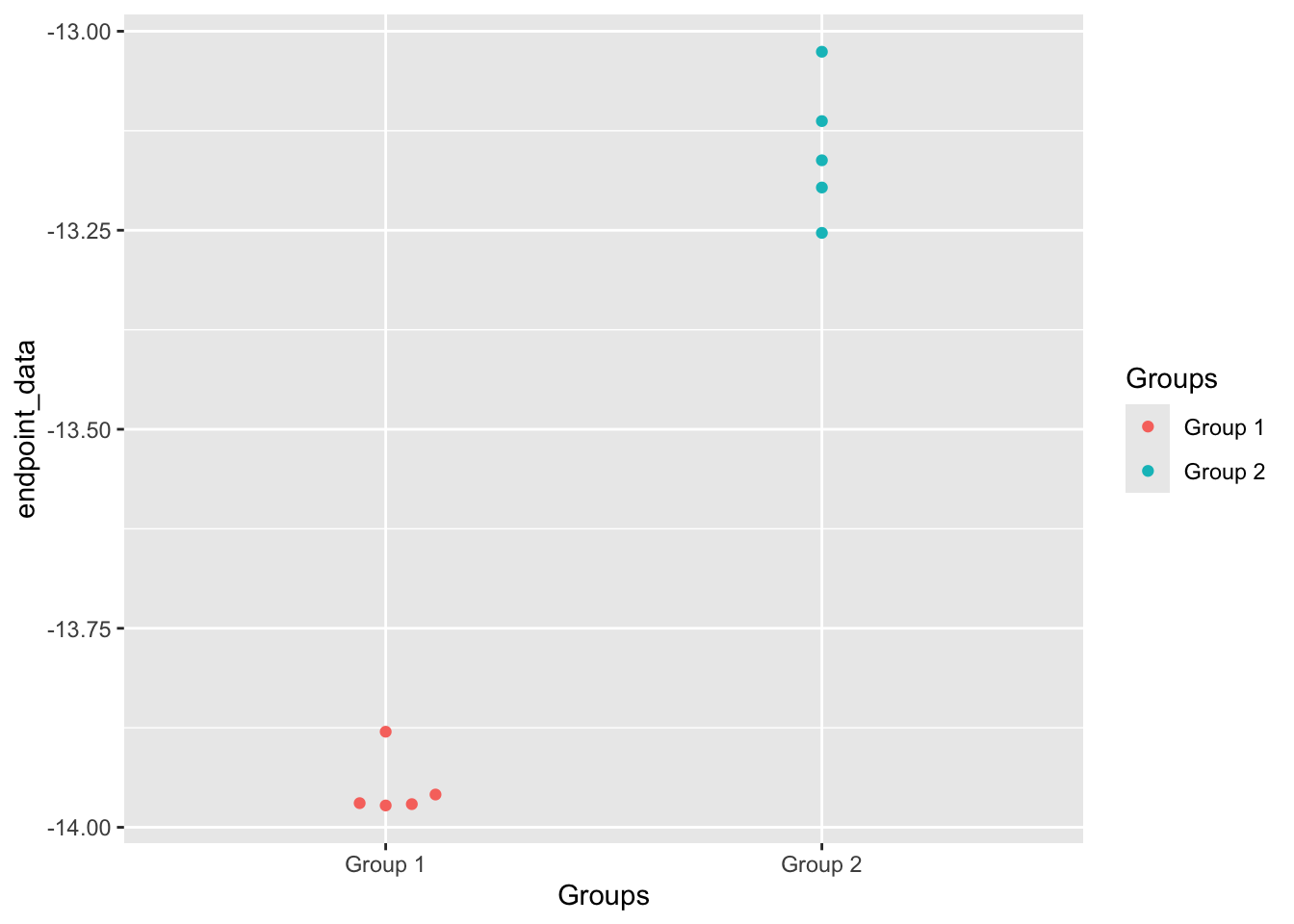
4.6.0.3 Perform statistical analysis on the data
## # A tibble: 1 × 10
## estimate estimate1 estimate2 statistic p.value parameter conf.low conf.high
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 -0.800 -14.0 -13.2 -18.8 0.00000268 5.63 -0.906 -0.695
## # ℹ 2 more variables: method <chr>, alternative <chr>4.7 ELISA data processing
We read ELISA plate in a 96 well plate using a plate reader. The plate reader generates the data in form of number in an excel sheet. We have created this pipeline/worksheet to bring out the information from the excl sheet to a tidy format in which the above created fitted model and endpoint titer functions can be applied.
4.7.0.1 Read in the first dataset
Below is the example ELISA data that has came straight out of the plate reader. This data is arranged in a 96-well plate format and contains Optical Density (OD) values.
## # A tibble: 6 × 12
## ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10 ...11 ...12
## <chr> <dbl> <dbl> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 5.199999999… 0.05 0.069 6.3E… 0.061 0.122 0.16… 0.145 0.135 6.80… 0.053 0.05
## 2 7.900000000… 0.098 0.069 6.80… 0.115 0.202 5.89… 0.134 0.069 0.106 0.05 0.075
## 3 8.899999999… 0.133 0.119 OVRF… 3.87 2.32 OVRF… 3.85 2.12 OVRF… 3.21 1.02
## 4 OVRFLW 3.46 1.16 OVRF… 3.80 2.36 OVRF… 3.70 1.49 OVRF… 3.68 1.63
## 5 3.815999999… 1.82 0.446 3.89… 3.42 1.13 OVRF… 2.33 0.608 OVRF… 3.41 1.10
## 6 OVRFLW 3.69 1.43 OVRF… 3.66 1.27 3.839 1.74 0.444 2.49… 0.637 0.7044.7.0.2 Tidy dataset 1
It is important to clean the data and arrange it in a format on which we can apply formulas and functions.
## # A tibble: 6 × 2
## well_id od_450nm
## <chr> <dbl>
## 1 A1 0.052
## 2 A2 0.05
## 3 A3 0.069
## 4 A4 0.063
## 5 A5 0.061
## 6 A6 0.1224.7.0.3 Read in the second data set
The second dataset contains the information such as groups, mouse id, and dilutions for the respective wells of the 96 well plate for the dataset-1.
## # A tibble: 6 × 12
## ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10 ...11 ...12
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 blank secon… naïv… 1A-1… 1A-1… 1A-1… 1A-2… 1A-2… 1A-2… 1A-3… 1A-3… 1A-3…
## 2 1A-4 (1/250 1A-4 … 1A-4… 1B-1… 1B-1… 1B-1… 1B-2… 1B-2… 1B-2… 1B-3… 1B-3… 1B-3…
## 3 1B-4 (1/250 1B-4 … 1B-4… 2A-1… 2A-1… 2A-1… 2A-2… 2A-2… 2A-2… 2A-3… 2A-3… 2A-3…
## 4 2B-1 (1/250 2B-1 … 2B-1… 2B-2… 2B-2… 2B-2… 2B-3… 2B-3… 2B-3… 2B-4… 2B-4… 2B-4…
## 5 3A-1 (1/250 3A-1 … 3A-1… 3A-2… 3A-2… 3A-2… 3A-3… 3A-3… 3A-3… 3A-4… 3A-4… 3A-4…
## 6 3B-1 (1/250 3B-1 … 3B-1… 3B-2… 3B-2… 3B-2… 3B-3… 3B-3… 3B-3… 3B-4… 3B-4… 3B-4…4.7.0.4 Tidy dataset-2
## # A tibble: 6 × 2
## well_id information
## <chr> <chr>
## 1 A1 blank
## 2 A2 secondary
## 3 A3 naïve (1/250)
## 4 A4 1A-1 (1/250
## 5 A5 1A-1 (1/1250
## 6 A6 1A-1 (1/62504.7.0.5 Merge dataset-1 (with OD information) with dataset-2 (with respective data information)
To create a complete full dataset with Groups, mouse-id, dilutions, and OD, we merged the dataset-1 and dataset-2 together. We also cleaned the data set so that mouse-ID and dilution columns are separate and have their own columns.
## # A tibble: 6 × 3
## well_id od_450nm information
## <chr> <dbl> <chr>
## 1 A1 0.052 blank
## 2 A2 0.05 secondary
## 3 A3 0.069 naïve (1/250)
## 4 A4 0.063 1A-1 (1/250
## 5 A5 0.061 1A-1 (1/1250
## 6 A6 0.122 1A-1 (1/6250## # A tibble: 6 × 4
## well_id od_450nm sample_id dilution
## <chr> <dbl> <chr> <chr>
## 1 A1 0.052 "blank" <NA>
## 2 A2 0.05 "secondary" <NA>
## 3 A3 0.069 "naïve " 1/250)
## 4 A4 0.063 "1A-1 " 1/250
## 5 A5 0.061 "1A-1 " 1/1250
## 6 A6 0.122 "1A-1 " 1/6250## # A tibble: 6 × 4
## well_id sample_id dilution od_450nm
## <chr> <chr> <dbl> <dbl>
## 1 A1 "blank" NA 0.052
## 2 A2 "secondary" NA 0.05
## 3 A3 "naïve " 250 0.069
## 4 A4 "1A-1 " 250 0.063
## 5 A5 "1A-1 " 1250 0.061
## 6 A6 "1A-1 " 6250 0.122